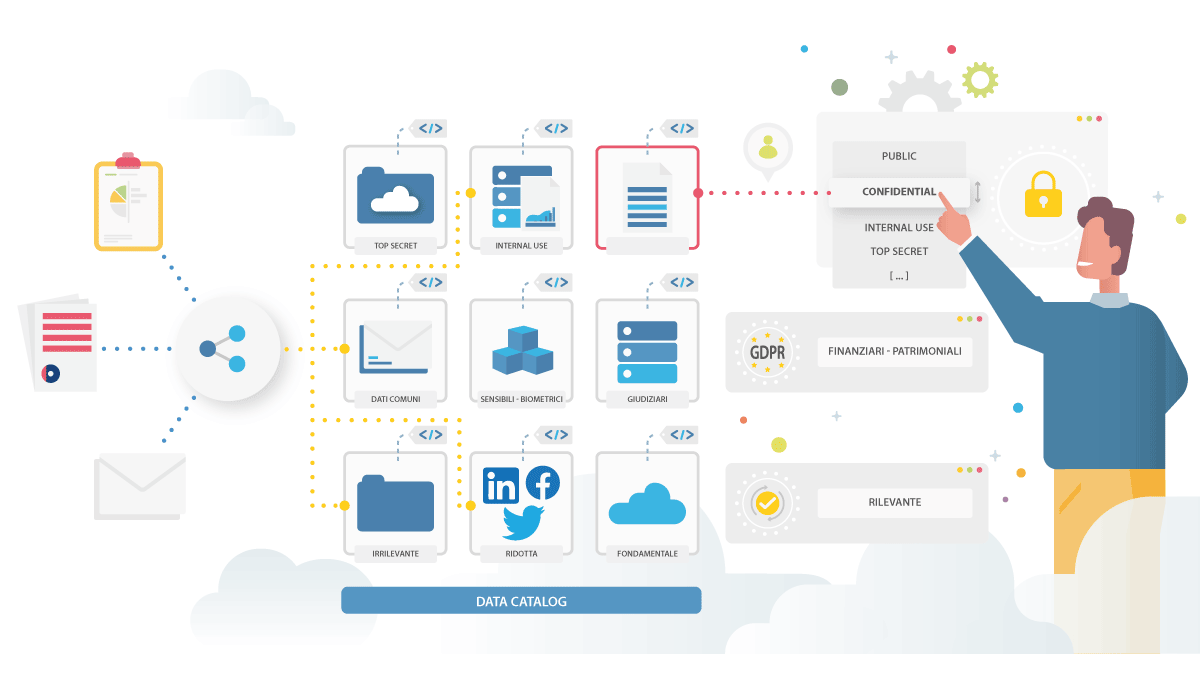
La classificazione dei dati è il processo di organizzazione del patrimonio informativo che prevede l’istituzione di una categorizzazione e la definizione di una o più tassonomie condivise da tutta l’azienda.
La presenza di un sistema di classificazione sostiene un’efficace determinazione delle priorità e dell’intensità degli interventi sui dati in base a criteri relativi alla criticità, alla sicurezza, l’accesso, all’utilizzo, alla privacy, all’etica, alla qualità, ai requisiti di conservazione dei dati.
Da quando le aziende hanno cominciato a comprenderne il reale valore per il business, si è resa più urgente la necessità di sviluppare una “cultura del dato”. Seguendo in concreto questi passi:
- identificazione delle informazioni rilevanti e critiche per il business,
- determinazione di una definizione valida per tutta l’azienda,
- specificazione del ruolo che giocano nei processi aziendali
- individuazione del legame con i dati fisici che le rappresentano nei sistemi informatici.
Solo gestendo tutte queste caratteristiche attraverso un sistema di metadati, è possibile disegnare e costruire impianti di controllo automatici in grado di determinare in modo efficiente e sostenibile il livello qualitativo delle informazioni critiche per un processo aziendale.
Una classificazione mirata, combinata con altre funzionalità di data management ha l’obiettivo di consentire un uso più consapevole e agevole dei dati come elemento chiave, ad esempio:
- nel processo di valutazione del rischio d’impresa,
- nella quantificazione del valore delle informazioni al fine di determinare vari livelli di sicurezza, qualità, riservatezza,
- nella risposta alle varie esigenze nascenti di business.
Come funziona la Data Classification?
La classificazione dei dati porta tipicamente alla realizzazione di un repository di metadati. Grazie a questo si possono prendere decisioni o applicare “tag” ad un oggetto dati per facilitare l’uso e la governance durante il ciclo di vita. Questo repository permette alle organizzazioni di focalizzare gli sforzi di analisi principalmente sui loro set di dati più importanti e critici. È fondamentale differenziare le informazioni a basso valore da quelle ad alto valore, definendo gli adeguati controlli di sicurezza per ciascun tipo di dati. Le informazioni più rilevanti richiedono ad esempio meccanismi più rigorosi di protezione. Classificare i dati è un processo che richiede tempo, molti passaggi e che ha rilevanti implicazioni legali e di business.
Tutto comincia con la definizione della policy di Data Governance, con la mappatura dei processi di business e l’inventario degli asset software e hardware in cui i dati risiedono. È necessario stabilire ed esercitare processi chiaramente definiti che regolino, ad esempio, le fasi di proposta, approvazione, pubblicazione, della semantica di un Business Term e che ne determinino i ruoli e le responsabilità.
Una volta definite le “regole guida” è necessario partire quanto prima:
- alla ricerca dei primi ambiti di applicazione e, con il coinvolgimento dei Data Owner, dei System Owner, Data Steward ecc., (nomi che ovviamente possono variare da azienda ad azienda, in funzione delle policy stabilite), identificare quali siano, all’interno dei processi che governano, le informazioni coinvolte, definirne una classificazione, la rilevanza, il profilo di rischio, i domini, le relazioni, i processi a monte e a valle, ecc.
- alla mappatura di chi ha accesso ai dati e la definizione dei ruoli delle persone che possono accedere a tali dati.
- all’approvazione di una policy di retention che, basandosi sulle caratteristiche del settore industriale a cui l’impresa appartiene, stabilisce per quanto tempo i dati vanno conservati, come vanno distrutti e attraverso quali mezzi.
- all’individuazione di quali dati sono per un uso interno selezionato, per un ampio uso interno, oppure possono essere resi pubblici o se hanno bisogno di essere mascherati sulla base delle indicazioni fornite dai Data Owner sia per la protezione della proprietà intellettuale sia per far fronte alle normative vigenti.
- alla definizione di un processo continuo di aggiornamento e arricchimento. Senza questo presidio costante la struttura e i contenuti del glossario diventano ben presto inutili perché non riescono ad adeguarsi all’evoluzione della domanda interna e perché non riescono a stare al passo con i cambiamenti dell’azienda.
È infine fondamentale assegnare un ruolo di presidio che sia a conoscenza dell’importanza dei dati e del loro valore nell’organizzazione e i cui compiti sono regolati nella politica di Data Governance, primi tra tutti il Chief Data Officer e i Data Owner.
Con la piattaforma Irion è possibile facilmente regolare l’accesso ai dati, rappresentare e navigare graficamente il patrimonio informativo, usufruire di funzionalità di ricerca avanzata per esplorare le informazioni, scoprire le connessioni per svelare il valore nascosto per il business, intercettare e minimizzare i rischi e velocizzare le decisioni manageriali.
Irion EDM: la piattaforma per la Data Classification e non solo.
Irion EDM è un sistema di Enterprise Data Management completamente metadata driven.
Utilizza gli strumenti di classificazione integrati con le più innovative tecnologie di data management di Irion EDM per:
- trovare, indipendentemente da dove risiedono, i data asset, sfruttando i numerosi connettori di Irion e utilizzando le funzioni avanzate di data discovery per accelerare il progetto;
- creare un Data Catalog condiviso contenente le informazioni rilevanti per l’azienda;
- stabilire ownership, regole di protezione, segregazione e qualità, policy di retention e tutto ciò che è rilevante per il business, nel pieno rispetto delle normative esterne vigenti e dei regolamenti aziendali;
- migliorare la comprensione dei processi aziendali e capire se i dati che usano sono di qualità, se sono soggetti a ferree regole normative (ad esempio quelle della privacy), da dove arrivano, se vengono riusati da altri uffici, l’importanza e il valore delle informazioni che gestiscono ottimizzandone l’impiego;
- rilevare le relazioni di Data Lineage per tracciare come le informazioni presenti nell’organizzazione vengono trasformate nel tempo, da chi e per quale processo aziendale.
Vuoi saperne di più?
Ti illustreremo con esempi pratici come le altre realtà
hanno già avviato la loro trasformazione.
Potrebbe interessarti anche:
No settings found for the grid #25.


