
Chiunque si occupi professionalmente o si interessi di dati certamente avrà sentito parlare di Data Mesh o sarà stato coinvolto in conversazioni su questo argomento, su cui si è dibattuto e scritto molto recentemente. Non che il mondo del data management sia stato avaro di novità in questi ultimi anni. Potremmo definirli hype, buzzword o paradigmi, in base al nostro grado di diffidenza o entusiasmo.
Ma Big Data, DataOps, Data Fabric, Adaptive Data Governance, Active Metadata, Augmented Data Management, Infonomics, fino ad arrivare al concetto di Data Driven Organization, sono solo alcuni dei termini che con finalità e da prospettive differenti hanno acceso i riflettori sul ruolo chiave che il patrimonio informativo, se opportunamente presidiato, può giocare nel raggiungimento degli obiettivi di un’impresa.
Insomma, i dati sono ormai di moda, c’è business, ci sono budget che le aziende stanno destinando alla cura dei propri data asset. E forse anche per questo cresce l’offerta non solo di tecnologie, ma anche di proposte architetturali e metodologiche in quest’ambito. Certamente la maggiore diffusione ed una ormai dimostrata potenziale efficacia delle metodologie e delle tecnologie di intelligenza artificiale e machine learning hanno sostenuto significativamente questo fenomeno.
Qualunque siano le ragioni di questa vitalità, ogni volta che un nuovo contributo metodologico si afferma nell’arena del Data Management, il quadro di insieme delle opportunità di evoluzione o consolidamento dell’impianto di gestione dei dati si fa più articolato e complesso.
Sinergie e contesti
Questo fatto rappresenta una sfida per i professionisti dei dati. Ognuno di questi modelli, metodi, framework si focalizza su aspetti specifici e può trovare applicazione in alcuni contesti, spesso in sinergia con altri. Potremmo ad esempio adottare una metodologia agile (DataOps) nei processi di sviluppo e gestione di un Data Catalog arricchito da metadati operativi (Active Metadata) che abiliti l’identificazione e la proposta di opportunità di automazione di processi ripetitivi di gestione dei dati (Augmented Data Management).
Non tutti i data paradigm sono poi applicabili in toto in tutti i contesti: in alcuni casi può aver senso applicare solo alcuni dei principi, dei pillar, dei fattori fondanti di un singolo framework. È perciò importante, per chi si occupa di dati a livello professionale, estrarre da questi paradigmi il valore che essi possono concretamente rappresentare per la propria azienda, declinandoli nei loro elementi costitutivi, nei loro fondamentali. È quello che proviamo a fare qui con il Data Mesh, partendo da quanto illustrato da Zhamak Dehghani, l’autrice di questo framework, nel suo testo di riferimento “Data Mesh – Delivering Data Driven Value at Scale”.
Cos’è il Data Mesh: 4 principi
Data Mesh è un framework di data architecture, fortemente orientato alla gestione dei dati analitici, disegnato sulla base di quattro principi:
- Domain Ownership
- Data as a Product
- Self-Serve Data Platform
- Federated Computational Governance
Principio di Domain Ownership
Nel Data Mesh i dati vengono organizzati in Domini: un Dominio comprende una serie di dati omogenei rispetto a determinati criteri (l’origine, l’aggregazione, il consumo) e viene posto sotto la ownership di un team interdisciplinare (business e ICT) di attori operanti nella sfera di competenza di questi dati. Il concetto di Dominio Dati è ispirato al modello DDD (Data Domain Design) per la progettazione del software. Questa scomposizione del patrimonio informativo in entità logicamente e organizzativamente distinte è rivolutiva rispetto ad un modello data lake, che vede il convogliamento di tutti i dati operativi in un unico ambiente.
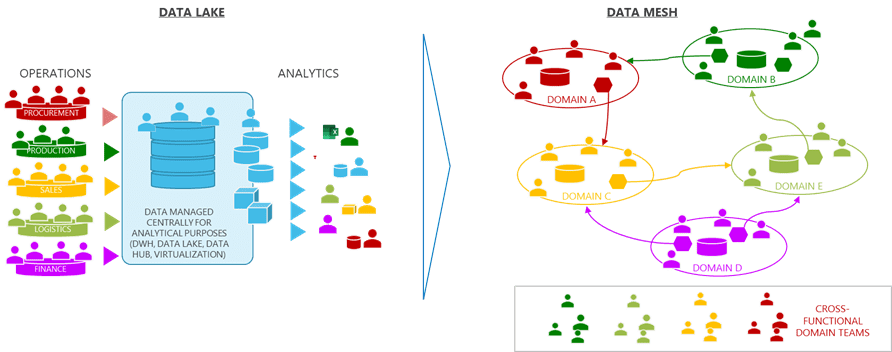
L’obiettivo della organizzazione per Data Domain è quello di attribuire la gestione dei dati ai soggetti che ne detengono la maggiore competenza, riducendo così l’entropia informativa derivante dalla concentrazione dei dati in un ambiente presidiato da figure che non hanno quella conoscenza di dettaglio dei singoli ambiti gestiti detenuta da chi vi opera direttamente. Tuttavia la sola applicazione del principio di Domain Ownership rischia di avere l’unico effetto di scomporre i dati in silos, situazione che in assenza di contrappesi creerebbe problemi di integrazione e coerenza complessiva.
Principio di Data as a Product
Ed è qui che interviene il secondo principio, che indica le modalità con cui i singoli domini interagiscono per garantire una gestione fluida ed efficiente dei processi aziendali. Come anticipato, il framework Data Mesh è orientato alla gestione dei dati analitici, risultanti da operazioni di aggregazione, integrazione, controllo della qualità. È però importante precisare che questi dati possono avere molte differenti finalità: impiego per scopo di analisi e ricerca (anche applicando tecniche e tecnologie di intelligenza artificiale e machine learning), rendicontazione interna o esterna (ad esempio per conformità a requisiti di reporting regolamentare), ma anche supporto a processi operativi a valle di quelli che li hanno originati.
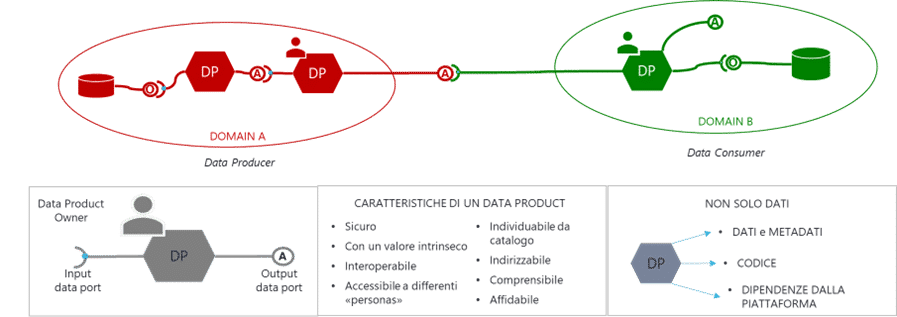
Un Data Product è una collezione di dati, corredati dal codice necessario per il loro consumo e dai metadati che ne descrivono le caratteristiche (contenuto, precisione e accuratezza, freschezza, fonti, modalità di utilizzo, ownership…); è realizzato all’interno di un Dominio Dati, partendo da dati originati dai propri processi operativi e/o da altri Data Product; è destinato al consumo da parte del Dominio stesso o di altri Domini. L’insieme dei Data Product è censito in un catalogo centrale e costituisce un reticolo di comunicazione che assicura un adeguato grado di integrazione e interoperabilità tra i Domini. Un Data Product deve rispondere ad un set minimo di otto criteri per essere considerato tale:
- Ricercabile
- Indirizzabile
- Comprensibile
- Affidabile
- Accessibile
- Interoperabile
- di Valore
- Sicuro
Vantaggi e criticità dei primi due principi
- garantiscono potenzialmente un’estrazione di maggior valore dai dati rispetto ad una architettura centralizzata, grazie alla distribuzione delle responsabilità sui dati dei singoli Domini alle migliori competenze di business e tecniche disponibili nell’organizzazione
- mitigando i rischi connessi ad una gestione a silo dei dati, attraverso uno scambio di Data Product autoconsistenti, auto-documentanti, corredati del codice necessario perché essi rispettino gli otto criteri sopra visti
D’altra parte, la produzione ed il consumo di Data Product da parte di ciascun Dominio Dati richiedono la disponibilità di adeguate tecnologie di data management e delle competenze tecniche necessarie per il loro impiego. Se ad ogni Dominio venisse delegato il compito di dotarsi in autonomia di questi strumenti, l’intera organizzazione correrebbe il rischio di dover gestire un’architettura ridondante, economicamente poco efficiente, con maggiori ostacoli potenziali rispetto ad alcuni dei criteri citati, ad esempio l’Interoperabilità.
Esistono poi policy interne e normative esterne ad un’organizzazione che coinvolgono dati gestiti da più domini; in generale tutta una serie di capability di data management non è specifica di un dominio: sarebbe più efficiente che tutte queste primitive e capability, nonché le relative competenze, fossero implementate e gestite in un solo punto e rese disponibili a tutti i Domini interessati.






