What is Data Mesh? How is it different from Data Lake, and where to begin with it? (Part 1)
Anyone who deals with data professionally or is interested in the subject will have heard of, or perhaps discussed, Data Mesh. This subject has recently been the focus of many writings and discussions. Not that there has been little new in the world of Data Management in recent years. We may define these new concepts as hype, buzzwords, or paradigms, depending on our degree of skepticism or enthusiasm. Still, Big Data, DataOps, Data Fabric, Adaptive Data Governance, Active Metadata, Augmented Data Management, Infonomics, up to Data-Driven Organization are just some of the terms that, with different purposes and from different perspectives, have brought into the limelight data assets. The latter, if appropriately managed, play the leading role in achieving business goals.
In short, data is a business trend today, and companies are allocating budgets to take care of their data assets. This may be one of the reasons for the increased demand not only for the technologies but also for architectural and methodological offers in this field. Clearly, the growing spread and proven potential effectiveness of Artificial Intelligence and Machine Learning methods and technologies have significantly supported this phenomenon.
Whatever the reasons for this viability, each new method contributed to the Data Management field makes the complete picture of development opportunities and data management system consolidation more elaborate and complex.
Different contexts and their combinations
This is a challenge for data professionals. Each of these models, methods, frameworks focuses on specific aspects and may find applications in different contexts, often in combination with others. For example, we could adopt an agile methodology (DataOps) in the processes of developing and managing a Data Catalog enriched with operational metadata (Active Metadata). It makes it possible to identify and suggest opportunities to automate repetitive data management processes (Augmented Data Management).
Not all data paradigms are fully applicable in all contexts. In some cases, it may make sense to apply only some principles, or pillars, founding factors of an individual framework. That is why it is important that those who deal with data extract the value from these paradigms to present it in practice to their company and thus show the constituent elements and fundamental parts of the data. That is what we try to do here with the Data Mesh. We begin with the text of reference, Data Mesh – Delivering Data Driven Value at Scale, by Zhamak Dehghani, the author of this framework.
What is Data Mesh: the four principles
Data Mesh is a data architecture framework strongly oriented towards the management of analytical data and based on four principles:
Domain Ownership
Data as a Product
Self-Serve Data Platform
Federated Computational Governance
The Domain Ownership principle
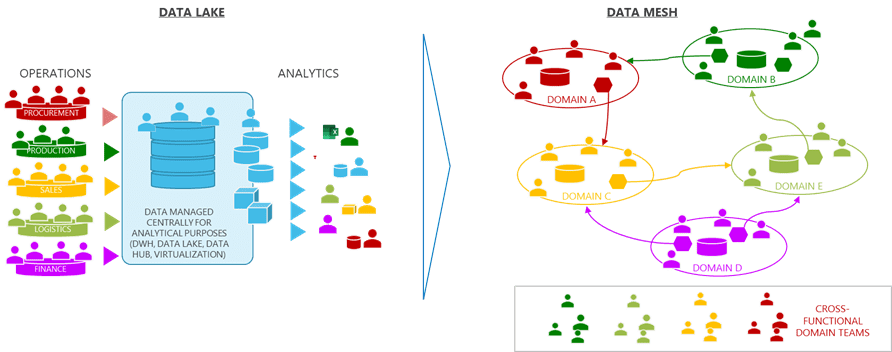
In the Data Mesh, data is organized in domains. A Domain contains data homogeneous with respect to determined criteria (origin, aggregation, consumption). It is under the ownership of an interdisciplinary (business and ICT) team of actors from the sphere of jurisdiction of this data. The concept of Data Domain is inspired by the DDD (Data Domain Design) model for software development. Such dismantling of data assets into logically and organizationally distinct entities is revolutionary compared to the Data Lake model, where all operational data is involved in a single environment.
Data Lake vs Data Mesh | illustration by Mauro Tuvo
Organizing by Data Domains aims to attribute the data management to those who have the best knowledge about it, thus reducing the data entropy that appears when the data is concentrated in an environment managed by those who have no detailed knowledge of individual areas, unlike those who directly work in the field. However, by applying just the Domain Ownership principle, we risk achieving no other effect but breaking down the data in silos. And unless counterbalanced, this situation would create issues with integration and overall consistency.
The Data as a Product principle
And this is where the second principle comes up. It indicates how individual domains interact to ensure smooth and efficient management of business processes. As already mentioned, the Data Mesh framework is oriented to managing analytical data resulting from operations of aggregation, integration, and quality checks. However, it is worth specifying that this data may have many different purposes. It can be used for analysis and research (also by applying artificial intelligence and machine learning techniques and technologies), internal or external reporting (for example, for complying with regulatory reporting requirements), as well as support operational processes downstream of those of origin.
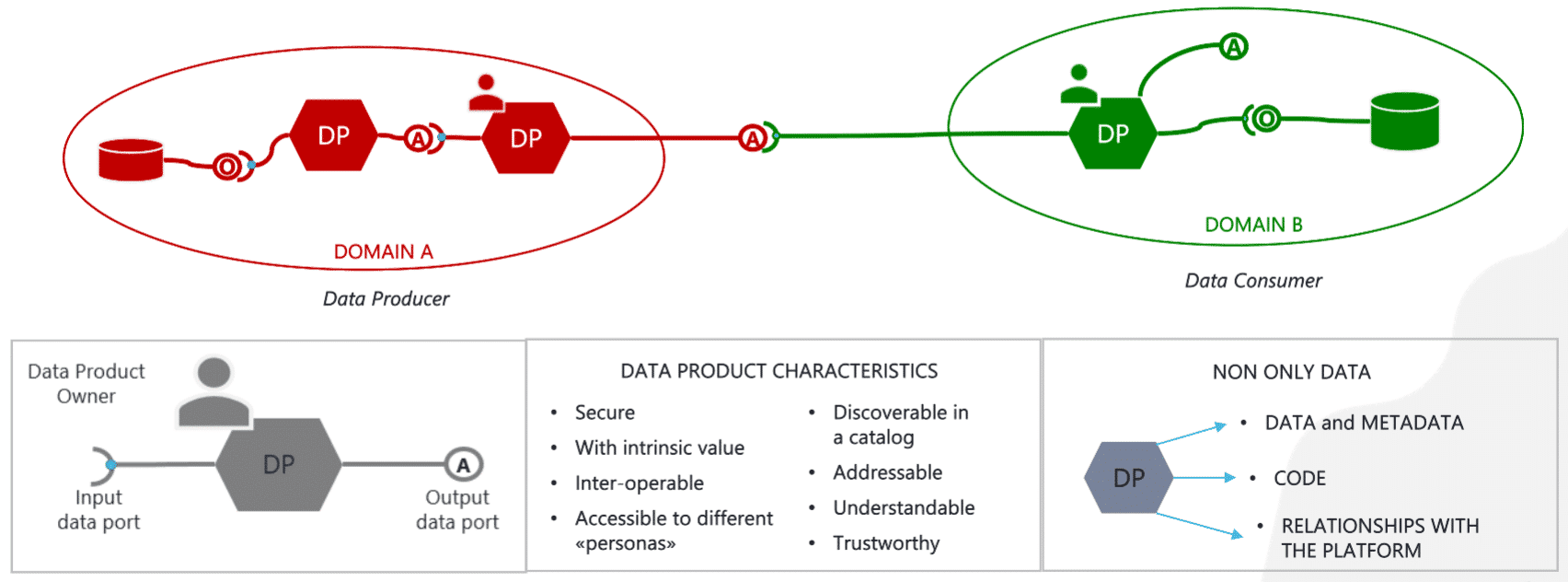
A Data Product is a collection of data along with the code necessary for its consumption and metadata that describes its characteristics (content, precision and accuracy, freshness, sources, use modes, ownership, etc.). A Data Product is created within a Data Domain from data originating from inner operational processes and/or other Data Products and intended for consumption by this or other Data Domains. A set of Data Products is registered in a central catalog and serves as a communication network that ensures adequate integration and interoperability between the Domains. A Data Product must meet a minimum of eight criteria to be considered as such:
Discoverable
Addressable
Understandable
Trustworthy
Accessible
Inter-operable
of Value
Secure
The advantages and concerns of the first two principles
enable potentially extracting more value from data compared to a centralized architecture thanks to distributed responsibility over the data of individual Domains to those business and technical units with the best knowledge within the company,
mitigate the risks of silos data management by exchanging self-consistent, self-documented Data Products with the codes necessary to respect the aforementioned eight criteria.
On the other hand, for every Data Domain, Data Product production and consumption require appropriate data management technologies and technical skills necessary for their use. If each Domain received the task of getting these tools autonomously, the entire organization would run the risk of managing a redundant, economically inefficient architecture. Potentially, there would be greater obstacles to the listed criteria, such as the inter-operability.
Besides, there are internal policies and external regulations involving data managed by several domains. In general, the data management capabilities are not domain-specific. It would be more efficient if all these primitives and capabilities, as well as the related skills, were implemented and managed in one point and made available to all Domains concerned.
At Irion as Principal Advisor, Mauro Tuvo has been supporting Italian and European organizations in the management of information assets for over thirty years, taking care of the development and oversight of offerings, solution design and development of business opportunities related to Enterprise Data Management issues. His activities over time have focused on Data Quality, Data Governance, and Compliance (GDPR, IFRS17, Regulatory Reporting), gaining extensive experience over the years in defining and applying methodologies that have seen him play a leading role in the market and in academic and policy contexts. An author of texts, articles and publications on topics related to data management, Mauro has lectured in master’s and graduate courses at the universities of Padua, Pavia and Verona. He participates as a speaker at conferences and seminars and has been a member of ABI Lab’s Information Governance Observatory since 2011.