
I rischi di ridondanza e inefficienza illustrati nel primo articolo sul Data Mesh sono in buona parte mitigati da un terzo principio del framework: la Self-Serve Data Platform. Si tratta di una componente dell’architettura Data Mesh che ha proprio lo scopo di ridurre il carico cognitivo dei team nei singoli Domini, rendendo loro disponibile una serie di capability che, opportunamente parametrizzate e integrate localmente, garantiscono una gestione agile, meno complessa dei Data Product.
Le capability di una Self-Serve Data Platform possono essere logicamente organizzate su tre piani, tra loro interconnessi:
- Il piano dell’esperienza a livello dell’intera Data Mesh rende disponibili funzionalità generalizzate per la ricerca di Data Product, per la gestione del data lineage, per il monitoraggio complessivo delle attività nell’organizzazione, per il supporto al rispetto delle policy globali;
- Il piano dell’esperienza relativa ad un singolo Data Product espone servizi per la gestione del suo ciclo di vita (Data Product journey): realizzazione, pubblicazione, data quality, documentazione, sottoscrizione, interrogazione, dismissione, …
- Il piano della data infrastructure gestisce le primitive di data management utilizzate dagli altri piani: il motore di query, la gestione della persistenza, il motore di regole, l’identity management…
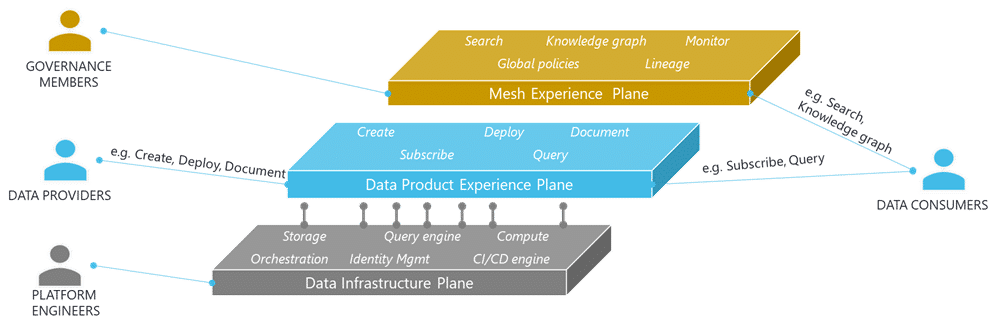
Questi tre piani comunicano tra loro e con l’esterno attraverso API. Una data platform unificata che rende disponibili ai Domini le capability generalizzate per la produzione e il consumo dei Data Product, limitandone la complessità alla sola dei parametri che ne determinano il comportamento, è un’espressione concreta del paradigma dichiarativo. Si tratta di un approccio di data management estremamente efficiente rispetto a quello imperativo, in cui invece lo strumento (o il linguaggio di programmazione) richiede allo sviluppatore che venga esplicitato ogni dettaglio tecnico relativo alle operazioni da eseguire sui dati. Ma qual è il modello di governo di questo framework; e in particolare chi gestisce le singole componenti (i Domini, i Data Product, i tre piani della Self-Serve Data Platform)?
Principio di Federated Computational Governance
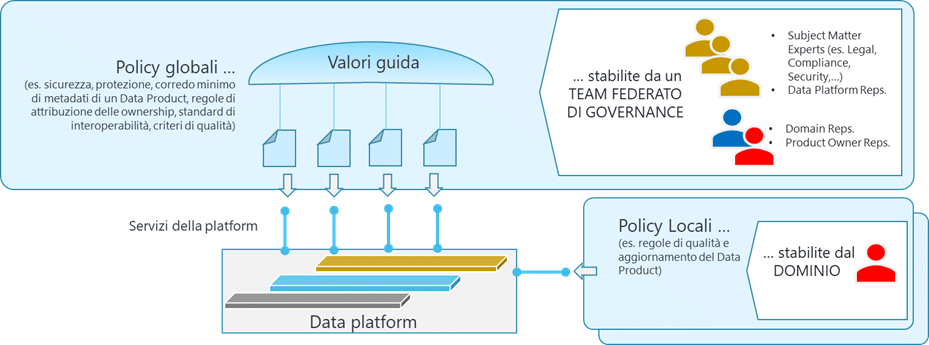
Il quarto e ultimo principio, la Federated Computational Governance indica il sistema di responsabilità che regola il funzionamento del Data Mesh: i processi, le componenti logiche coinvolte, i singoli ruoli con le relative competenze. Un modello federato di governance sostiene uno degli obiettivi chiave del framework: l’attribuzione del più alto grado possibile di autonomia e responsabilità al Dominio Dati.
- A livello centrale sarà collocato il solo presidio delle policy che devono essere rispettate da tutti i Domini (ad esempio per la conformità a requisiti normativi, la tassonomia dei criteri di qualità dei dati, gli standard di sicurezza e protezione dei dati) e la gestione della Self-Serve Data Platform.
- A livello dei singolo Dominio Dati è prevista la costituzione di un team interdisciplinare (Data Domain Team), costituito dalle figure che detengono le competenze di business e tecnico-informatiche più approfondite all’interno dell’organizzazione sui dati gestiti nel Dominio stesso. Il Team ha autonomia e responsabilità nella gestione operativa dei dati di propria competenza, nella produzione e nella gestione di propri Data Product, nel consumo e impiego dei Data Product che ha sottoscritto e al cui accesso è abilitato. Le sole regole al cui rispetto deve conformarsi sono quelle valide a livello globale, in particolare legate all’utilizzo delle capabilities esposte dalla Self-Serve Data Platform e alle policy globali. Fatto saldo questo vincolo, il Data Domain Team ha totale autonomia nella definizione delle proprie policy interne e delle caratteristiche del Data Product che gestisce.
- In particolare all’interno dei Domini sono collocati i Data Product Owner, con il compito di gestire lungo il loro intero ciclo di vita uno o più Data Product realizzati all’interno dei Dominio. È responsabile del rispetto da parte di questi Data Product delle policy globali e in generale dei sette criteri minimi: Ricercabile, Indirizzabile, Comprensibile, Affidabile, Accessibile, Interoperabile, di Valore, Sicuro. La realizzazione fisica del Data Product è affidata ad un Data Product Developer, anch’esso collocato nel Dominio.
- Nei Domini sono anche presenti i Data Product Consumer, ovvero le figure che utilizzando i Data Product realizzano analisi, report, dashboard (data analyst), addestrano ed esercitano modelli di intelligenza artificiale e machine learning (data scientists), realizzano altri Data Product (Data Product Developer), realizzano applicazioni e servizi per la gestione operativa del proprio Dominio (application developer).
- La Self-Serve Data Platform è gestita da un team (Data Platform Team) costituito da due figure principali: un Data Platform Developer, che sviluppa e gestisce i servizi erogati dai tre piani della piattaforma, e un Data Platform Product Owner che, analogamente al Data Product Owner, gestisce i servizi erogati dalla piattaforma ai domini come dei prodotti, curandone la correttezza e l’esperienza in ottica “dichiarativa” lungo il loro intero ciclo di vita.
Gli impatti organizzativi
In un’architettura Data Mesh a regime non esiste una figura di CDO (Chief Data Officer) o di CDAO (Chief Data & Analytics Officer). Il coordinamento centrale del Data Mesh è affidato ad un team (Team Federato di Governance) costituito da rappresentanti dei Data Domain Team, dei Data Product Owner, del Data Platform Team e da subject matter expert competenti su tematiche di sicurezza, protezione, compliance, affari legali. A questo team federato è attribuita la responsabilità di definire le policy globali che dovranno essere applicate da tutti i Domini e, se necessario, implementate nei servizi della Data Platform.
Si può fare?
Da questa veloce carrellata sui quattro principi del Data Mesh è facile cogliere il carattere rivolutivo di questo framework rispetto a modelli basati unicamente sulla gestione centralizzata dei dati analitici: esso comporta cambiamenti rilevanti sul modello organizzativo e sull’impiego delle tecnologie di data management. I casi di applicazione concreta, almeno nel nostro paese e a nostra conoscenza, non sono molti e nella maggior parte di casi non sono ancora giunti a coprire l’intera organizzazione. La sua adozione non può che avvenire gradualmente, per passi successivi.
Un primo esercizio propedeutico ad una eventuale introduzione potrebbe essere quello di isolare un dominio dati autoconsistente, su cui verificare la possibilità di avviare un progetto che veda la presenza di un team interdisciplinare con l’obiettivo di realizzare uno o più deliverable sotto forma di Data Product. Sulla base dell’esito di questa esperienza sarà possibile valutare la fattibilità di una applicazione del Data Mesh su scala più larga.
È comunque importante sottolineare che nei quattro principi del framework ogni azienda può trovare spunti interessanti, ne citiamo solo alcuni:
- un differente bilanciamento delle responsabilità in materia di cura dei dati a favore dei ruoli “locali” ai dati di un determinato ambito come risultato di un programma di data literacy e di promozione di una cultura del dato;
- un approccio interfunzionale (business e IT) alla gestione dei data asset come cardine di un solido modello di Data Governance;
- l’attenzione al corredo di metadati per garantire una corretta comprensione delle caratteristiche di un set informativo (sia esso un report, un flusso di dati o un Data Product vero e proprio) da parte dei potenziali utilizzatori (data consumer);
- un orientamento ad un approccio dichiarativo nella scelta o nell’implementazione di tool di data management, che garantisca la più efficace e sostenibile esperienza di utilizzo delle loro capabilities da parte di soggetti con differenti gradi di competenza, riducendone la complessità tecnica.






