The ABI Lab working group gives priority to Data Governance projects
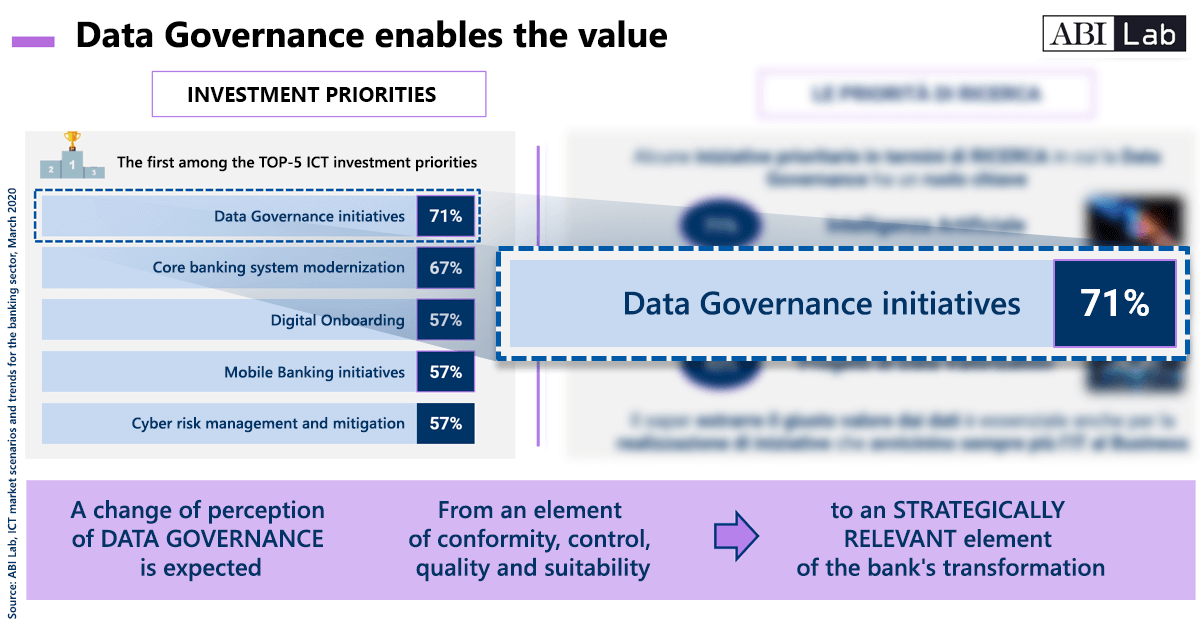
Data Governance initiatives will be the absolute priority for ICT investments in banking in 2021. This is what emerges from the ABI Lab research presented at the closing of the 2020 working groups.
Other priorities for 2021 are core banking system modernization, digital onboarding, mobile banking, cyber risk management, and mitigation.
Metadata plays and will continue to play a decisive role in this scenario, as shown by Irion at the Information Governance between strategy and implementation webinar. But how to make it work for us?
Metadata all around
Most cooking recipes are arranged into sections: preparation time, difficulty, ingredients, and preparation. Pharmaceutical leaflets always have separate paragraphs describing the indications, dosage, and side effects.
Recipes and leaflets are two of the many metadata systems we know. They put the necessary information in order and allow retrieving it effortlessly and more precisely. Even more so in our work, with the ever-increasing volumes and heterogeneousness of the data we use and process.
What metadata do we mean?
- business metadata, a Business Glossary that describes the entities involved in our work and the relationships between them;
- physical metadata, a data dictionary that describes the characteristics of the data managed in our computer systems;
- specific metadata characteristic of the industry sector or particular purposes we need to support;
- operational metadata, parameters that can run our data quality and integration engines, etc., in case of using metadata-driven data management platforms.
These metadata categories communicate with each other via relations, such as vertical Lineage, or mapping business terms with the fields they represent in computer systems.
Where to start: from model to requirements
It all begins with gathering requirements for new applications or new data elaboration processes, the data pipelines. These are generally available in documents or gathered in interviews, so the necessary characteristics are in an unstructured form. But it is possible to organize them in a metadata system. Similar problems have similar features that can be expressed in a model.
This way, data governance no longer follows and reconstructs the history (as we have to do for regulated environments) but is its active integral part. This practice is called Data Governance by Design. For mapping a new process, we would gather the data on the company’s various activities to evaluate the process itself, the rules applied, the actors involved, etc. All this data can be represented with metadata. It clarifies the requirements of the solution to implement in a more formal, precise way.
Knowledge Graph and “connected” metadata
Mapping these elements and their relationships makes it possible to explore the characteristics as desired, for example, by navigating a Knowledge Semantic Graph (one of the pillars of the Data Fabric design concept). It allows to visually explore all the elements of a process, facilitating their governance. Further on, depending on the requirements model, one can implement the process and activate the application or the process that will generate and use new metadata.
In particular, the applications built on a metadata-driven Enterprise Data Management platform, possibly connected to the metadata that stands for the requirements. New metadata, such as the results of Data Quality controls, will be gathered as the solution is executed. The requirements metadata, both technical/actuating and operational, is indispensable for applying DataOps principles. The active use of all this metadata is yet another pillar of the Data Fabric design concept.
How to make the best use of these metadata assets?
We can try to put them at the service of the business. For this, we are to identify the entities and functions that need data to function, understand which data they need, and see if we can help them find the answers by exploring our metadata.
This principle forms the basis for the service-oriented Data Governance paradigm, which ABI Lab has often spoken about in the past year. One of the ways to deliver these services is a graphic representation in response to an internal Customer request that also explains the logical path that has led to this response. Data assets governance is commonly believed to improve decision-making processes, sustain digital transformation and make the company truly data-driven.
Gartner analysts (Adaptive Data and Analytics Governance to Achieve Digital Business Success, 21 July 2020, Saul Judah, Remi Gulzar) have identified the progression of four distinctive Data Governance styles. They called it Adaptive Data Governance. New types of metadata correspond to each style. To be ready for this evolution, we need to enhance metadata assets to deliver new services and respond to new needs.
How can we get ready and prepare our metadata for these challenges?
By working on three levels:
- adopting methods and techniques based on the use of metadata to analyze and implement data-intensive solutions;
- using metadata-driven Enterprise Data Management technologies, tools for metadata representation via semantic graphs, application management platforms that support an AGILE approach;
- spreading the culture: not only on data literacy but also on metadata literacy
One doesn’t need to be a metadata expert. It is enough to recognize them as such to make the best use of the available information for one’s purposes and the company’s interests.
ABI Lab Information Governance working group
Want to know more?
We will provide you with illustrative examples of how other organizations have already started their transformation.


