
Augmented Data Quality means applying advanced functions to automate some Data Quality (DQ) processes with the help of “active metadata” and such technologies as Artificial Intelligence and Machine Learning.
Today, data specialists face increasingly complex challenges: growing data volumes, increasingly heterogeneous data sources, and the need for an “AI-ready” information ecosystem. These needs have guided Irion in developing DAISY – Data Artificial Intelligence System. And starting in 2025, we are the only Italian company recognized in Gartner’s Magic Quadrant for Augmented Data Quality Solutions (download the report).
Many DQ tasks can be automated, for example profiling, data matching, automatic linking between entities, merging, cleansing, monitoring, automatic alignment between business and IT control rules, troubleshooting anomalies or poor quality warnings. Governing data means creating and maintaining the conditions that allow to have the necessary data when needed, ensure they are complete and accurate, and thus maximize the benefits of their use. But what if the information is unreliable? If the data are erroneous, what will be the consequences for decision-making?
AugmentedAugmented Data Quality aims at ensuring reliable and high quality data, which is vital to organizations. Its purpose is also to cut down on manual tasks in DQ practices,reducing human intervention in favor of automated workflows within processes and, consequently, saving time and resources..
How does it work?
Information has always been fundamental for businesses. But if, on the one hand, data value becomes more and more a factor of competitive advantage, on the other hand, the exponential growth of the available data makes it difficult to identify those useful at a given time and for a certain purpose. It also becomes challenging to understand data origin and accountability, verify their reliability and freshness, find out the possible regulatory requirements to comply with.
In this ecosystem, according to Gartner, Augmented Data Quality can be implemented in three specific “areas”:
- Discovery. These are functionalities developed by leveraging the capabilities of active metadata and reference data in distributed environments with a high number of data assets (both internal and external) in the cloud, including multicloud or on-premise conditions. Techniques to locate where data resides, classify—for example—sensitive data for privacy purposes, automatically identified thanks to their characteristics, or detect correlations between data residing in different data sources.
- Suggestion. It is possible, for example—again starting from metadata—to profile business terms in order to suggest an automated enrichment of the Data Catalog, present certain attributes as potential candidates to be linked to a specific entity, recommend remediation actions to correct any detected anomalies by learning from user behavior over time, highlight possible lineage connections between business process entities, propose data control rules, or leverage information inferred from reading application logs.
- Automation. Many common practices can be automated, such as correcting anomalous cases with a confidence level above a certain threshold, or applying rules to specific types of data, such as those considered sensitive for privacy purposes. Equipping oneself with a verbalization engine can, for example, drastically reduce the time needed to produce up-to-date documentation in compliance with rules and control procedures, ensuring consistency between Business and Technical rules in the event of an inspection.
To meet specific operational needs, DAISY introduces intelligent assistance features, such as the Copilot Pipeline & Rule Wizard, which drastically reduces the time needed to configure controls. Smart Data Discovery also supports users in the automatic detection of anomalies or unexpected relationships within datasets, even across large volumes. DAISY also enables Automatic Vertical Lineage, allowing users to visualize how data changes affect processes and outputs—particularly useful in audit and compliance processes.
But let’s delve deeper with a practical example. As Gartner highlights in the diagram below, in a typical data quality process it is possible to identify certain “actions” that can be automated at each stage.
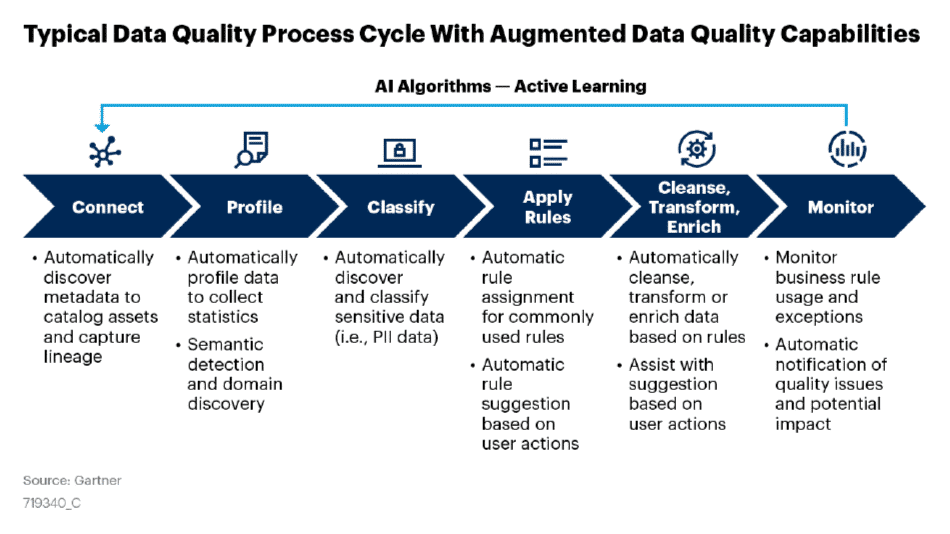
All these premises demonstrate that, beyond an effective advanced data quality tool capable of verifying—through the execution of checks—the compliance of data with a series of technical and business requirements, it is also essential to adopt a Data Governance tool: a metadata management system that handles a “business information ID card,” including all business entities (semantics, ownership, impacted processes, quality and retention rules…) and technical entities (formats, source applications, physical controls…) that define them, their attributes, and mutual relationships. These two components are closely interconnected, just as data quality and data governance are inseparable disciplines that support each other. Irion’s EDM platform offers, in a single integrated environment, all the tools needed to support flexible, scalable, and future-proof data quality and data governance systems tailored to the context.
These innovations have been developed to meet concrete market needs, with an increasing focus on delivering data that is ready for AI and decision-making.
Bring your data into the AI era: discover how Irion supports you with Augmented Data Quality




